One of the cool new features in SQL Server 2014 is delayed durability (available in all Editions), which is described in detail in Books Online here.
I think I’m going to see a lot of people turn this on, as you can get a profound increase in transaction throughput with the right workload. However, I also think a lot of people are going to turn this on without realizing the potential for data loss and making the appropriate trade off.
Why can it give a throughput boost?
I put together a contrived workload with a small table where 50 concurrent clients are updating the same rows, and the database log is on a slow I/O subsystem. Here’s a graph showing my test:
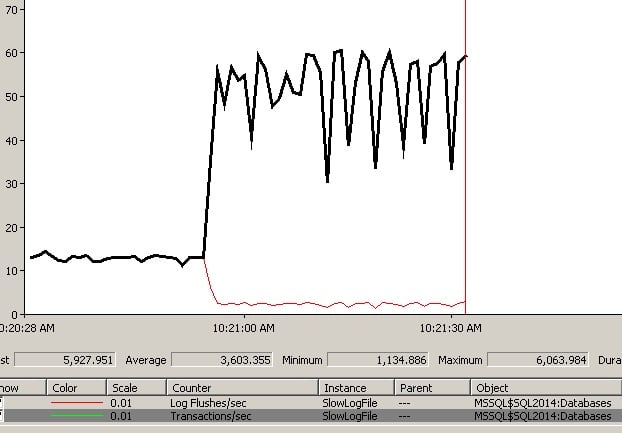
At the obvious change point, that’s where I enabled delayed durability, with all transactions being forced to use it. Before the change, the number of Transactions/sec is equal to the number of Log Flushes/sec, as each transaction is holding locks that block all other transactions (I told you it’s a contrived workload). So why the profound jump in Transactions/sec when I forced delayed durability?
Under normal circumstances, when a transaction commits, the commit doesn’t complete until the log block (see this blog post for more details) containing the LOP_COMMIT_XACT log record for the transaction has been flushed to disk and the write is acknowledged back to SQL Server as having completed, providing the durability of the transaction (the D in the ACID properties of the transaction). The transaction’s locks cannot be dropped until the log flush completes.
In my workload, all the other transactions are waiting for the one that is committing, as they all need the same locks, so Transactions/sec is tied to Log Flushes/sec in this case.
With delayed durability, the transaction commit proceeds without the log block flush occurring – hence the act of making the transaction durable is delayed. Under delayed durability, log blocks are only flushed to disk when they reach their maximum size of 60KB, or roughly every 1ms, whichever comes first. This means that transactions commit a lot faster, hold their locks for less time, and so Transactions/sec increases greatly (for this workload). You can also see that the Log Flushes/sec decreased greatly as well, as previously it was flushing lots of tiny log blocks and then changed to only flush maximum-sized log blocks.
Note:
- I was forcing all transactions to be delayed durable, but the facility exists to make the delayed durability choice per transaction too (see Books Online for more details).
- There’s a bit more to the log block flushing too: under delayed durability, a log block will flush when it fills up, or if a non-delayed durable transaction commits, or if the new sp_flush_log proc is executed, or after 1ms.
My good friend Aaron Bertrand over at SQL Sentry has a long post about delayed durability that looks into its performance implications in a little bit more depth so I recommend you check out his post as well.
So this looks great, for the right type of workload. But I bet you’re thinking:
What’s the catch?
Your transactions aren’t durable when they commit. Simple.
Now you may be thinking that if the system crashes, the most you’re going to lose is up to 60KB of transaction log. Wrong. If that last log block contains the LOP_COMMIT_XACT log record for a long-running transaction, when the system crashes, and that log block isn’t on disk, that whole transaction will roll back during crash recovery. So the potential for work/data loss is greater than just 60KB.
And there’s more:
- Log backups will not back up that unflushed log block, as it’s not on disk, so non-durable committed transactions may not be contained within a log backup.
- Non-durable transactions that have committed are not protected by synchronous database mirroring or a synchronous availability group either, as these rely on log block flushes (and transmission to the mirror/replica).
For critical transactions, an sp_flush_log can be used, or per-transaction delayed durability used instead.
So the million-dollar question is:
Should I enable delayed durability?
It depends. Is your business comfortable making the throughput vs. durability trade off? Does enabling it give a throughput boost? If yes to both, go ahead. If no to either, don’t enable it. That’s a very simplistic way of thinking about it, but that’s what it boils down to really.
There are lots of other things you can do to increase the throughput and performance of the transaction log, and I explained them in a blog post series:
- Trimming the Transaction Log Fat
- Trimming More Transaction Log Fat
- Transaction Log Configuration Issues
- Transaction Log Monitoring
As I stated above though, I think a lot of people are going to be wowed by the throughput boost (if their workload benefits) from delayed durability and see this as a no-brainer, without considering the potential for data loss.
Tempting, isn’t it?
46 thoughts on “Delayed Durability in SQL Server 2014”
What would you recommend to get a log flush once per second? Seems not to be build it.
Let me make sure I understand – you mean a way to only have a things durable once per second? There isn’t a way to do that. I can see why that might be interesting, but that would involve a lot of caching in memory.
Btw, please specify a real name/email when posting in future as I’m seeing you make up random ones from the same email address.
I’m guessing the question was inspired by MySQL as there is a setting that can be configured this way (innodb_flush_log_at_trx_commit). Their logging design is significantly different from SQL Server’s, though.
I’m guessing tobi’s idea, or at least what I see as a good in-between, is having a background process (a job running an endless loop maybe) executing:
exec sp_flush_log
WAITFOR DELAY …
For a given databases, or for each database on the instance.
Yes, but that’s only useful if your workload is such that there’s a very low amount of transaction log being generated, less than would take to fill up a 60KB log block in one second (minimum time period for an Agent job). Even then, it still doesn’t remove the dangers of data loss, just randomly makes the chance smaller.
That’s why I mentioned the job running an endless loop, where the time between flushes would actually be decided by the WAITFOR DELAY interval, which can be as short as 1ms.
Not bullet-proof by any means as far as data protection goes, but might be considered as decent in-between arrangement.
Does this guarantee that when transaction 3 is written to disk, transaction 1 & 2 also have been written to disk?
If so, this might be useful in DataMart loader scenarios.
Yes it does, as log blocks are flushed in the order they are created always.
Hey
I recently did a brief 3 part series looking at why you might or might not use delayed durability including some rough and ready tests on performance. https://rule30.wordpress.com/2014/03/09/delayed-durability-in-sql-server-2014-part-1-introduction/
I hope it helps someone
Cheers
S
“Should I enable delayed durability? It depends.”
Crivens – never saw that coming … LOL! ;-)
Thanks for the info Paul. I believe this is Enterprise edition only. Correct?
I believe it’s in all Editions – don’t see anything in BOL that says Enterprise-only.
Paul,
Did you run this test on a system with the log file on an SSD? It would be interesting measure/isolate delayed durability’s impact an SSDs as they use page (their page) sized writes, typically 4-8K much larger than that of an HDD. If log records written are less than block size there’s potential for wasted IO capacity. With delayed durability you’re storing data in larger/fuller pages on the disk.
Anthony
Nope – wasn’t a perf test, just an illustration of the potential effect on a workload. But if you want to go ahead, I’d love to read about the results… :-)
Hi Paul,
Assume I have turned on Delayed Durablity for transaction T1. T2 and T3 are normal transactions but started after T1. So, does that mean T2 and T3 will be written before T1? If yes, does SQL Server sort the LSN numbers ( reorder transactions ) while performing recovery?
No – as soon as a non-delayed durable transaction commits, the log block is flushed to disk. It’s impossible to reorder transactions – that breaks all kinds of things.
Can you use Delayed durability in combination with AlwaysOn? (I guess not)
Yes – it works with all SQL Server HA/DR features. You need to be careful though, because if the log block doesn’t flush on the primary/principal, it won’t be copied to the replica/mirror, as the log block flush is what triggers the copy. So after a crash, even with synchronous AG/mirror, a committed transaction may not be on the replica/mirror.
What happens if you do a commit on the primary with delayed durability (sync replication)? I assume it will wait for the commit on the secondary replicas before it’s committed on the primary. So the bottleneck will be my secondary replica. Or do I have to enable Delayed Durability also on my secondary replicas to prevent this?
No – when a delayed durable transaction commits, there is no log block flush locally, so nothing is sent to the sync replica. When a log block flush actually occurs, the local log write cannot be signaled as complete until the log block as been written to the sync replica’s log drive too.
Delayed durability cannot be switched on/off on the replicas, as they are read only. If the primary is set to use delayed durability, that setting will be present in the replicas as well, but is not used unless that replica becomes the primary. I.e. the behavior of delayed durability only affects the primary replica for log block flushes and log blocks sends to the non-primary replicas.
Hi MR Paul!
At a database, recovery model is simple and delayed_durability = Allowed.
After running checkpoint command the fn_dblog function shows 3 records.
After executing the following command:
Begin Tran
Insert into tbl values (1, ‘Paul’)
Commit With (Delayed_Durability = ON)
select * from Fn_dblog(null, null)
The fn_dblog function shows 6 records!!!
Even after running the following script:
Begin Tran
Insert into tbl values (1, ‘Paul’)
Commit With (Delayed_Durability = ON)
Shutdown with nowait
And after the service starts, the record was added to the table!!!
what does happen?
The log blocks are also flushed to disk every 1ms.
Therefore, how to Delayed_Durability causes data loss?
If the server crashes before the log block is flushed. 1ms is still a window of time. I know of businesses that have experienced that and had to turn delayed durability off.
If the log blocks are flushed to disk every 1ms or (60KB), how Delayed_Durability can be useful?
I think it’s not useful.
Because log block flushing is asynchronous and on busy systems will be flushed much more frequently than that.
Delayed durability set to force will not improve bulk insert performance. It is suitable only for small volume commit. I enabled this in my development environment by using select * into to insert 4 million records. Forced durability took 2 minutes 1 sec to complete the insert where as disabled mode executes in 35 seconds.
Absolutely. It’s designed to help workloads with frequent, very small log flushes.
If you are using a synchronous form of HA then I wouldn’t use delayed durability,
Here I blv transaction will get more slow as log will not be hardened on log disk on secondary replica if primary log block is not full.
Please correct me.
Not quite. The transaction will actually be faster, as it won’t have to wait for the log harden on the secondary copy, as it’s the log block flush which triggers the remote copy. But I wouldn’t use it with sync AG/DBM because if there’s no log block flush, there’s a window where you could crash, failover, and lose data. Very small window but still a window.
Hi Paul,
Thank you for the Article and detailed explanation with follow ups.
In one of our critical system, we had huge write log waits. We enabled the Delayed Durability, which improved the performance significantly our Response time went down 50%. Write log waits went down 80% log flush went down 6
Here is my Question
1.) What happens when there is a fail over from active to passive node? will there be a data loss?
2.) Is there a way we can gracefully shutdown by doing a log flush and shutdown? or Should we disable the Delayed Durability then shutdown the instance?
Thank you,
CT
You’re welcome.
1) If a transaction commits on the active node and the log block is not written to disk before the failover, the transaction will be rolled back as part of the failover. So ‘yes’.
2) When delayed durability is enabled, the log flushed automatically every 1 millisecond, so if you stop activity before doing the failover, you’ll be fine.
Thank you Paul. That is helpful
.
If the commit is executed with delayed durability and there is a system crash before the log is written completely, will there be a complete rollback or will the database be inconsistent?
Rollback – just normal crash recovery.
hi Paul
I thought, by design tempdb behaves with durability enabled long before , however when you look at database options it can be enabled or disabled ( Sql 2017 ent)
Does this make a different how tempdb behaves?
You can think of tempdb as behaving that was as it doesn’t flush the log to disk on a commit, only when a log block fills up, as there’s no log durability requirement for tempdb.
I know this is seven years after the fact, but thank you for another great article. I’ve learned tons from you over the years; this is my first comment, but I wanted to say thanks first.
Question: In this article you state:
“There’s a bit more to the log block flushing too: under delayed durability, a log block will flush when it fills up, or if a non-delayed durable transaction commits, or if the new sp_flush_log proc is executed, or after *1ms*.”
I believe this 1ms figure is referenced in another article of yours as well. The problem is, I can’t seem to find this documented anywhere else. In books online (current for SQL2019, but the language is verbatim in SQL2016):
“SQL Server does attempt to flush the log to disk both based on log generation and on *timing*, even if all the transactions are delayed durable. This usually succeeds if the IO device is keeping up. However, SQL Server does not provide any hard durability guarantees other than durable transactions and sp_flush_log.”
So my question is: where does the 1ms figure come from? was this a SQL2014-era target, or does something similar still hold? I’m asking because this would put a very fine point on the risk window (~1ms), but then I also can’t say I really understand the guidance on running sp_flush_log at intervals as stated in the Documentation. That discussion leaves one with the very scary impression that a system with, say, a single transaction (and no other activity) that didn’t hit 60KB could hang out indefinitely (certainly longer than 1ms) until something external triggered the flush. But 1ms is a very tolerable window (if reliable) for most practical purposes (where you’re already willing to give up a little durability), and it then seems like sp_flush_log would only really be useful if you wanted to run at specific times–i.e. just before taking a LOG backup and/or as part of a server shutdown stored proc or something.
Sorry for running on there. Thanks again!
The 1ms is undocumented and it’s a fixed value.
awesome, thank you!
Regarding a controlled FCI Failover, the SQL shutdown would checkpoint the database first, this would also flush the tran log buffer and thus no Delayed Durability data loss. Is this correct ? I am happy for the potential data loss in exceptional circumstances of a crash, but not in controlled FCI fail-overs such as those instigated by Cluster Aware Updating.
Correct – there’s only the potential for data loss with an uncontrolled failover.
Sorry for the…wait for it…*delayed* reply. I’m trying to my understanding of the interaction between DELAYED_DURABILITY and a controlled failover. What you and Rick say above makes sense to me, and is how I think things “should” work: i.e. a non-catastrophic shutdown implies a checkpoint and a log flush. However, the official documentation (which, again, also does not mention the – very important! – 1ms log flush interval) concludes with this very scary-sounding paragraph:
“For delayed durability, there is no difference between an unexpected shutdown and an expected shutdown/restart of SQL Server. Like catastrophic events, you should plan for data loss. In a planned shutdown/restart, some transactions that have not been written to disk may be saved to disk before shutdown, but you should not plan on it. Plan as though a shutdown/restart, whether planned or unplanned, loses the data the same as a catastrophic event.”
source: https://learn.microsoft.com/en-us/sql/relational-databases/logs/control-transaction-durability?view=sql-server-ver16#-shutdown-and-restart
I’m not sure how to take this paragraph (perhaps it’s just base-covering?) Put another way: is a planned shutdown WITHOUT delayed_durability somehow “safer” / less-catastrophic than a planned shutdown WITH delayed_durability (above and beyond what I’m already willing to accept turning DD on in the first place)? The paragraph above seems to imply this, but I have a hard time undestanding how or why. Curious your thoughts, and thanks so much again for the knowledge and insight!
I believe this is some CYA or is just plain wrong – otherwise nobody would ever enable delayed durability.
In SQL Server 2016 Standard Edition, when executing single INSERT queries in parallel threads, the write transactions/sec count is approximately twice as high as the log flushes/sec count. Additionally, we occasionally observe log records larger than 512 bytes being written.
As far as I know, only the Enterprise Edition supports the group commit feature. Could you help identify the cause of this behavior? Is it possible that multiple commits are being grouped and flushed in a single IO operation?
Do you have delayed durability enabled?
PS You said log records larger than 512 bytes – do you mean log blocks? A log block is what is flushed, which contains one or more log records.