A while back I kicked off a survey asking what mechanism you use for running your regular SQL Server database maintenance.
Here are the results:
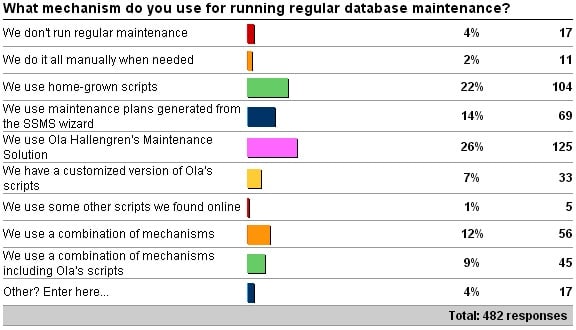
The “Other” responses were:
- 7 x “A combination of maintenance plans generated from SSMS wizard and a home-grown index maintenance script”
- 5 x “Combo of own and modified scripts of Michelle Ufford”
- 2 x “Home-grown scripts for main databases and SSMS wizard in some simple cases”
- 1 x “A combination of enterprise backup agent and AdaptiveIndexDefrag“
- 1 x “A combination of home-grown scripts and Ola’s scripts (for Indexing and Statistics)”
- 1 x “Combination of Ola’s scripts (indexes/stats) and homegrown (DBCC and backups)”
The main purpose of this survey is to show people that there are freely-available and comprehensive scripts that you can download to help run your regular database maintenance, and that many, many people use them in production.
I don’t like to recommend using the SSMS Maintenance Plan Wizard. It has quite limited options, has had a number of high profile bugs in the past, and to this day, even in SQL Server 2012, it still allows you to perform regular shrink operations without any warning as to the side-effects.
Home grown scripts are OK, but time after time when I’m reviewing client maintenance scripts I see coding errors, lack of logging of what happened, and lack of useful error handling. An example of a common error is in code to figure out which indexes are fragmented, where the results from sys.dm_db_index_physical_stats are not filtered by alloc_unit_type_desc, so there are false positives from LOB_DATA and ROW_OVERFLOW_DATA allocation units. In one client, many of their large clustered indexes had no logical fragmentation but were being rebuilt every night needlessly because of benign LOB_DATA fragmentation, generating a ton of extra transaction log that had to be backed up.
More than 40% of the almost 500 respondents use some or all of Ola Hallengren’s Maintenance Solution, and I always recommend our clients download and play around with Ola’s scripts before asking us to write customized code for them, or at least let us use Ola’s code where possible to save them consulting time. Ola’s Maintenance Solution has won multiple awards and is very widely used in the SQL Server community. Ola’s scripts are the gold standard and allow you to do backups, index and statistics maintenance, and consistency checks.
One of the cool things about using Ola’s scripts is that they’re tested constantly by thousands of installations around the world and they’re very robust. If you’ve never seen them, or want to upgrade your database maintenance, check them out!
14 thoughts on “Easy automation of SQL Server database maintenance”
We use Ola’s scripts and they are great. Using these scripts instead of the MMS wizard reduced our maintenance window by 4 hours. What is your view on switching recovery models from full to simple before the maintenance window and then switching back to full once it is complete? Trying to reduce my VLF’s.
No – absolutely not as that breaks the log backup chain. You could potentially switch to bulk_logged to reduce the amount of log generated, as long as there are no user-generated changes happening at the same time. You run the risk of losing them if the system crashes before your next log backup (that will contain the minimally-logged operation) and the data files are damaged – you lose the ability to do a tail-of-the-log backup. See https://www.sqlskills.com/blogs/paul/a-sql-server-dba-myth-a-day-2830-bulk_logged-recovery-model/
Thank you for making that clear. In your experience is it quite common to switch in to Bulk _logged mode for the maintenance tasks to be carried out?
I’d say it’s common for those who are able to recover after a crash with no possibility of losing user transactions.
We also use Ola’s maintenance solution and its great. Regardless of method for re-indexing a major friction point with IT is the amount of log generated during the weekly re-indexing process. For a 1TB DB upwards of 300 GB of log can be generated. This causes mirroring backlogs/delays and also cause Data Protection Manager to take a long time to sync up with its off-site DPM partner server (sometimes several Days!). As we approach a time where we will have a Second site on warm standby we know that this delay in having off-site backups available during the vulnerable period after Index maintenance could be the Achilles heal. We are considering a larger pipe between the sites for Avail Group but to generate less burst Log activity would be great.
To mitigate this we have done 2 things with only minimal impact. First we spread out the weekly re-indexing by introducing Delays, purposely slowing a 3 hour process to about 8 hours or so. Secondly “some” key tables are maintained by a process that runs hourly resulting in Just in Time re-indexing.
Should we go through all tables one by one and try to rationalize specific criteria for Index maintenance in order to dramatically lessen the re-indexing frequency for a large part of the tables?
Yes – and only remove fragmentation from those tables and indexes where it’s really going to benefit. Another thing you can do is only use REORGANIZE instead of REBUILD. Then you can do staggered fragmentation removal like I describe in http://sqlmag.com/blog/efficient-index-maintenance-using-database-mirroring
See also Merrill Aldrich’s relatively new Rules-Driven Maintenance Scripts: http://sqlblog.com/blogs/merrill_aldrich/archive/2012/08/01/rules-driven-maintenance.aspx
They preference tables to drive all the maintenance activity.
When I initially responded to this survey, my answer was that we used maintenance plans generated by SSMS.
I had downloaded Ola’s maintenance solution but never taken the time to play with it and learn how to use it.
Well, I finally took the time to do so and found it quite easy to install and learn how to use.
After some successful tests, I am now in the process of rolling this out to all my production servers.
I’m particularly pleased with the ability to rebuild indexes on an “as needed” basis instead of rebuilding ALL indexes.
This used to cause a huge spike in the size of my log file backup.
I expect this problem of log file spikes to now go away.
Best wishes to everyone…
One of my clients wanted me to setup Daily full, hourly diff and daily log backups (with SIMPLE recovery model). Their reasoning is it requires fewer clicks to restore the database without restoring tlog backups which is done regularly in DEV. Naturally this goes against every bit of best practice I’ve ever learned. Other than not having PIT recovery and using ALOT more disk space than necessary can you think of any other reasons this is a bad idea?
Confused a bit as you say daily log backups with SIMPLE – you can’t do log backups in SIMPLE. Can you clarify?
Hi Paul,
In one of my sharepoint database 1.7 TB specific to single database with below parameters it is running 1:45 Min for Index Optimize job OLA script. Is there any way we can reduce the time? We are using Standard edition
EXECUTE dbo.IndexOptimize
@FragmentationLevel1 = 5,
@FragmentationLevel2 = 30,
@LogToTable = ‘Y’
Really? You think 1min 45s it too long for analyzing and potentially fixing fragmentation in a 1.7TB database?
Hi Paul,
In SQL server 2012 Enterprise x64 with 2tb of data and with the following service pack version:
Microsoft SQL Server 2012 (SP1) – 11.0.3000.0 (X64)
Oct 19 2012 13:38:57
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on Windows NT 6.0 (Build 6002: Service Pack 2)
Product Version: 11.0.3000.0
Service Pack: SP1
would you recommend rebuilding indexes online, or would you be running into possible index corruption?
Regards,
H
You’re not going to get possible index corruption using online index rebuild in any version if you’re on the latest build and there are no known bugs. Whether you use offline or online index rebuild depends on your environmental requirements and constraints, but I don’t have a reason NOT to recommend online.