Last week I kicked off a survey about how you monitor your database mirroring sessions. See here for the original post.
Here are the results of the survey:
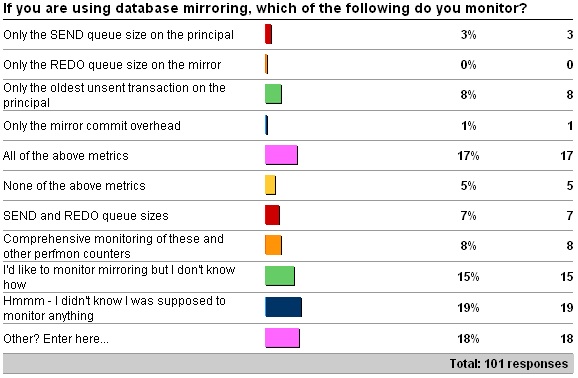
The "Other" values were:
-
6 people monitor mirroring session state changes
-
One uses a 3rd-party product to do monitoring
-
One monitors response time for the application
-
One made a sheep joke – very good
-
8 people don't use mirroring, which isn't relevant here
In my opinion, the only people who are monitoring mirroring correctly are those who picked:
-
All of the above metrics
-
SEND and REDO queue sizes
-
Comprehensive monitoring
The problem with database mirroring is the hype around it providing instant failure detection and instant failover.
These properties are mythical.
In reality, the time it takes to detect a failure depends. The time it takes to failover depends. I've written about these in the past:
It is absolutely essential that you monitor at least the SEND queue size and the REDO queue size of a mirroring session.
-
The SEND queue size shows how much transaction log has been generated on the principal server but has not yet been sent to the mirror server. If it is non-zero, means the mirroring state is not SYNCHRONIZED, meaning that an automatic failover cannot occur. Furthermore, the SEND queue size is an indication of the data loss that will occur if the principal database were to suffer a disaster. You need to monitor this to ensure the size of the SEND queue does not exceed your maximum allowable data loss SLA (or RPO) for the database being mirrored.
-
The REDO queue size shows how much transaction log exists in the mirror database that has not yet been replayed on the mirror database. (Remember that log records just have to be hardened on the mirror database's log drive, not replayed – that is done as an ongoing process on the mirror server.) If a mirroring failover occurs, the mirror database cannot be accessed until all transaction log records in the REDO queue have been replayed on the mirror database – essentially crash recovery has to occur. The larger the REDO queue, the longer a failover will take. (Remember that in Enterprise Edition, fast recovery comes into play and the database becomes available after the REDO phase of recovery has completed and before the UNDO phase begins.) You need to monitor this to ensure the size of the REDO queue does not exceed your maximum allowable downtime SLA (or RTO) for the database being mirrored.
The oldest unsent transaction is another way to monitor the instantaneous amount of data loss you would suffer if the principal database suffered a disaster. It applies in all modes of database mirroring, because even if you are using synchronous mirroring, the principal and mirror can become disconnected, or you may pause mirroring.
The mirror commit threshold is good to monitor to see what kind of delay is being added to transactions waiting to commit on the principal because their log records have not been acknowledged as written to disk on the mirror.
Books Online discusses all of these here.
There are a bunch of performance counters for database mirroring but unfortunately the Books Online entry for them is very sparse. The best place these are documented online that I know if is a blog post of mine from 2008 (which the KB article about configuring database mirroring actually references too). See SQL Server 2008: New Performance Counters for Database Mirroring.
For those of you who don't know how to monitor database mirroring, there is a half-decent tool in SSMS called the Database Mirroring Monitor. It allows you to easily configure alert thresholds the four metrics I discuss above.
Here's a picture of it running inside the VPC I use to demo mirroring for the MCM prep videos.
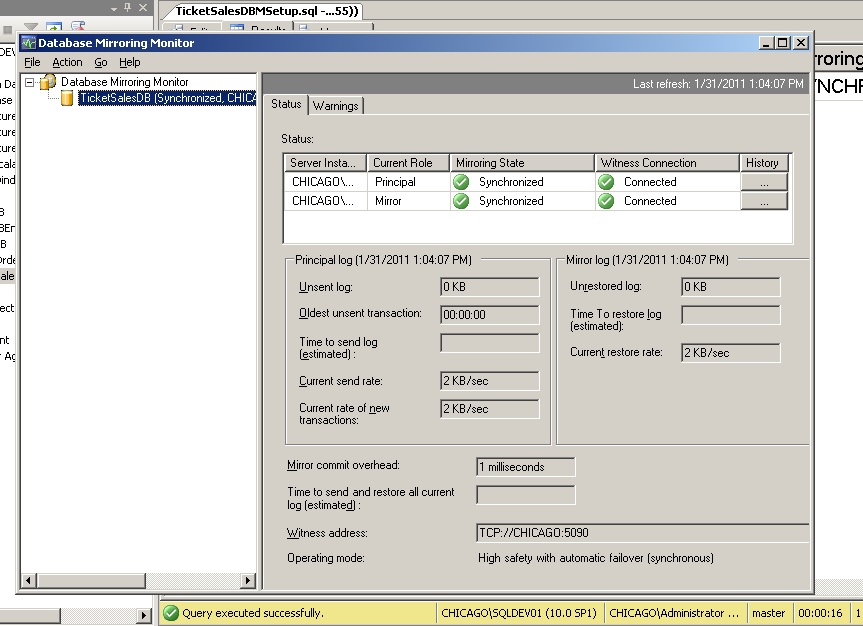
It's very easy to use and you can read more about it in Books Online here.
MCM Robert Davis (blog | twitter) also covers monitor database mirroring in his excellent book – see here.
Bottom line: you must monitor database mirroring to ensure the mirroring session is preserving your downtime and data-loss SLAs.
Happy monitoring!
7 thoughts on “Importance of monitoring a database mirroring session”
Good timing on this post! I just happened to have discovered my mirroring session got paused overnight. I resumed the mirror session and it looks like it’s going to take about 4 hours to get synchronized again. My question is in regards to the Oldest Unsent Transaction field in the Mirroring Monitor dialog box. On my system, the session has been resumed now for an hour and transactions are flowing to the mirror server, yet the Oldest Unsent Transaction time keeps rising. The value reported is now an hour longer than when I initially resumed it. Since the transactions are sent in the order they occurred, shouldn’t this time be decreasing as the mirroring session catches up?
You can disregard my last comment.. I figured it out :-)
Hi Shaun,
I know it is a long time ago, but can you recall your findings regarding ‘Oldest Unsent Transaction time keeps rising’. I have been seeing times of 14 minutes, but there are no unsent logs.
Regards
Kamal
Another good reason to monitor the Redo Queue is if you are routinely creating database snapshots of the mirror database (Ent. Ed. only feature). As you already said, crash recovery has to be run on the database when it fails over. The same is true when a database snapshot is created. Crash recovery runs in the context of the snapshot. It has to apply all of the records in the Redo queue before the snapshot can be brought online. This means that a large Redo queue can significantly extend the amount of time it takes to create a database snapshot.
Hi, I just set up mirroring for the first time and it says all is synchronized but the values for everything are always zero for all databases, even when I up the history grid to show 2 days’ worth of info. This doesn’t seem right but I can’t find tips on this situation anywhere. Thoughts?
It could be that there’s not enough traffic or latency on the mirroring session to show any problems.
nice artical